Many thanks to Sage for allowing infoDOCKET to share the full text version of this article.
Title
Students’ Artificial Intelligence (AI) literacy: An Exploratory Study
Authors
Mor Deshen
Ramat Gan Academic College, Israel
Bar Ilan University, Ramat Gan, Israel
Noa Aharony
Bar Ilan University, Ramat Gan, Israel
Source
Journal of Librarianship and Information Science
DOI: 10.1177/09610006261442178
Abstract
This research aims to uncover the factors that might be associated with higher education students’ Artificial Intelligence (AI) literacy. Understanding these factors is crucial, as it can lead to numerous benefits, such as preventing skill gaps and ensuring workforce adaptability. The study used quantitative methodology. One hundred ninety students responded to an online quantitative questionnaire. Measures include a demographic questionnaire, as well as established validated and reliable questionnaires including AI literacy scale, the personal trait of openness to experience, the cognitive appraisals of threat and challenge, and four sub-scales of AI Device Usage Acceptance (AIDUA): social-influence, hedonic-motivation, willingness to accept AI usage, and positive emotions toward AI. Students’ AI literacy correlated positively with their openness to experience, challenge, social-influence, hedonic-motivation, willingness to use, emotions toward AI, and Generative AI (GenAI) usage. The study also provided insights into gender and age differences. As AI literacy is a crucial factor in our professional and daily life, the current findings suggest opportunities for enhancing it through tailored educational programs that foster relevant personal traits, attitudes toward AI, and curriculum development in higher education. This study is significant as it explores the relationship between students’ AI literacy and various variables that have not yet been examined thoroughly, in the context of the rapidly evolving use of GenAI chatbots.
Direct to Full Text Article

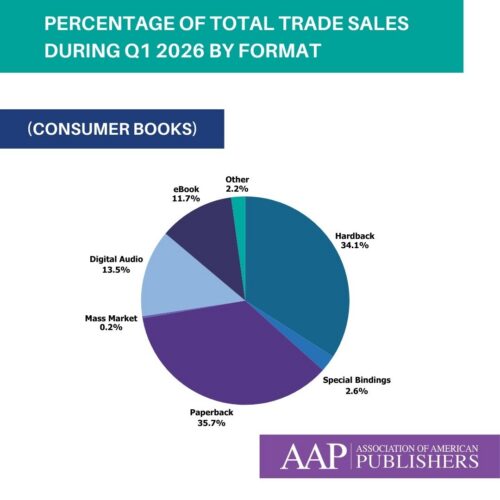 Trade (Consumer Books) Revenues by Month
Trade (Consumer Books) Revenues by Month