Joan Giner-Miguelez Universitat Oberta de Catalunya (UOC) Barcelona Supercomputing Center
Abel Gómez Universitat Oberta de Catalunya (UOC)
Jordi Cabot Luxembourg Institute of Science and Technology
University of Luxembourg
Source
Scientific Data (Sci Data) 12, 61 (2025) DOI: 10.1038/s41597-025-04402-4
Abstract
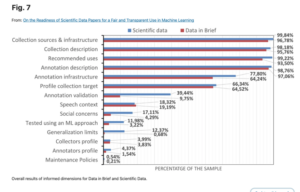
To ensure the fairness and trustworthiness of machine learning (ML) systems, recent legislative initiatives and relevant research in the ML community have pointed out the need to document the data used to train ML models. Besides, data-sharing practices in many scientific domains have evolved in recent years for reproducibility purposes. In this sense, academic institutions’ adoption of these practices has encouraged researchers to publish their data and technical documentation in peer-reviewed publications such as data papers. In this study, we analyze how this broader scientific data documentation meets the needs of the ML community and regulatory bodies for its use in ML technologies. We examine a sample of 4041 data papers of different domains, assessing their coverage and trends in the requested dimensions and comparing them to those from an ML-focused venue (NeurIPS D&B), which publishes papers describing datasets. As a result, we propose a set of recommendation guidelines for data creators and scientific data publishers to increase their data’s preparedness for its transparent and fairer use in ML technologies.
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area.
He earned his MLIS degree from Wayne State University in Detroit.
Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.