Large language models have a documented tendency to “hallucinate,” or make up false information. In one highly-publicized case, a New York lawyer faced sanctions for citing ChatGPT-invented fictional cases in a legal brief; many similar cases have since been reported. And our previous study of general-purpose chatbots found that they hallucinated between 58% and 82% of the time on legal queries, highlighting the risks of incorporating AI into legal practice. In his 2023 annual report on the judiciary, Chief Justice Roberts took note and warned lawyers of hallucinations.
Source: Stanford HAI
Across all areas of industry, retrieval-augmented generation (RAG) is seen and promoted as the solution for reducing hallucinations in domain-specific contexts. Relying on RAG, leading legal research services have released AI-powered legal research products that they claim “avoid” hallucinations and guarantee “hallucination-free” legal citations. RAG systems promise to deliver more accurate and trustworthy legal information by integrating a language model with a database of legal documents. Yet providers have not provided hard evidence for such claims or even precisely defined “hallucination,” making it difficult to assess their real-world reliability.
[Clip]
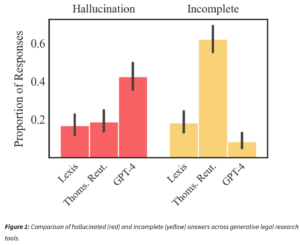
In a new preprint study by Stanford RegLab and HAI researchers, we put the claims of two providers, LexisNexis and Thomson Reuters (the parent company of Westlaw), to the test. We show that their tools do reduce errors compared to general-purpose AI models like GPT-4. That is a substantial improvement and we document instances where these tools can spot mistaken premises. But even these bespoke legal AI tools still hallucinate an alarming amount of the time: these systems produced incorrect information more than 17% of the time—one in every six queries.
[Clip]
These systems can hallucinate in one of two ways. First, a response from an AI tool might just be incorrect—it describes the law incorrectly or makes a factual error. Second, a response might be misgrounded—the AI tool describes the law correctly, but cites a source which does not in fact support its claims.
Thomson Reuters is aware of the recent paper published by Stanford.
We are committed to research and fostering relationships with industry partners that furthers the development of safe and trusted AI. Thomson Reuters believes that any research which includes its solutions should be completed using the product for its intended purpose, and in addition that any benchmarks and definitions are established in partnership with those working in the industry.
In this study, Stanford used Practical Law’s Ask Practical Law AI for primary law legal research, which is not its intended use, and would understandably not perform well in this environment. Westlaw’s AI-Assisted Research is the right tool for this work. To help the team at Stanford develop the next phase of its research, we have now made this product available to them.
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area.
He earned his MLIS degree from Wayne State University in Detroit.
Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.