Can artificial intelligence (AI) match human skills for finding obscure connections between words? Researchers at NYU Tandon School of Engineering turned to the daily Connections puzzle from The New York Times to find out.
Source: NYU Tandon
[Clip]
With Julian Togelius, NYU Tandon Associate Professor of Computer Science and Engineering (CSE) and Director of the Game Innovation Lab, as the study’s senior author, the team explored two AI approaches. The first leveraged GPT-3.5 and recently-released GPT-4, powerful large language models (LLMs) from OpenAI, capable of understanding and generating human-like language.
The second approach used sentence embedding models, namely BERT, RoBERTa, MPNet, and MiniLM, which encode semantic information as vector representations but lack the full language understanding and generation capabilities of LLMs.
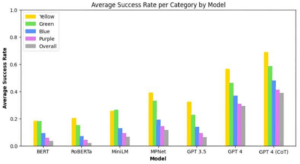
The results showed that while all the AI systems could solve some of the Connections puzzles, the task remained challenging overall. GPT-4 solved about 29% of puzzles, significantly better than the embedding methods and GPT-3.5, but far from mastering the game. Notably, the models mirrored human performance in finding the difficulty levels aligned with the puzzle’s categorization from “simple” to “tricky.”
“LLMs are becoming increasingly widespread, and investigating where they fail in the context of the Connections puzzle can reveal limitations in how they process semantic information,” said Graham Todd, Ph.D. student in the Game Innovation Lab who is the study’s lead author.
The researchers found that explicitly prompting GPT-4 to reason through the puzzles step-by-step significantly boosted its performance to just over 39% of puzzles solved.
The Connections puzzle published each day by the New York Times tasks players with dividing a bank of sixteen words into four groups of four words that each relate to a common theme. Solving the puzzle requires both common linguistic knowledge (i.e. definitions and typical usage) as well as, in many cases, lateral or abstract thinking. This is because the four categories ascend in complexity, with the most challenging category often requiring thinking about words in uncommon ways or as parts of larger phrases. We investigate the capacity for automated AI systems to play Connections and explore the game’s potential as an automated benchmark for abstract reasoning and a way to measure the semantic information encoded by data-driven linguistic systems. In particular, we study both a sentence-embedding baseline and modern large language models (LLMs). We report their accuracy on the task, measure the impacts of chain-of-thought prompting, and discuss their failure modes. Overall, we find that the Connections task is challenging yet feasible, and a strong test-bed for future work.
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area.
He earned his MLIS degree from Wayne State University in Detroit.
Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.