Research Tools: A New Resource to Explore Library of Congress Transcription Datasets
As a reader of the Signal, you may already be familiar with By the People, the Library of Congress’s crowdsourcing program that allows volunteers to transcribe, review, and tag digitized pages from the Library’s collections. Further, you may already know that, once completed, those transcriptions are released to the Library’s website, where they help make items more accessible and discoverable. However, were you aware that in addition to those transcriptions, By the People also produces and releases datasets of completed transcriptions to the Library’s website?
To date, there are 19 By the People datasets in the Selected Datasets Collection, and that number will continue to grow as more transcription campaigns are completed by volunteers. Each available dataset package consists of a .CSV file containing data exported from Concordia (the software behind By the People) and a README with information about the transcription campaign and the structure of the dataset. The .CSV file includes all the transcriptions and tags that were created by volunteers, opening up the possibility for computational research across collections with By the People transcriptions.
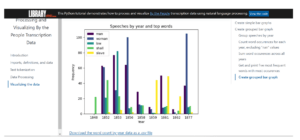
If you are now feeling simultaneously excited about these datasets, but unsure where to start, we have just the resource for you! Library staff have created a Python tutorial for using By the People datasets from four campaigns with materials related to the women’s suffrage movement (from the Susan B. Anthony Papers, Carrie Chapman Catt Papers, Elizabeth Cady Stanton Papers, and Mary Church Terrell Papers) to experiment with Natural Language Processing and create simple visualizations. The tutorial is organized in a series of Jupyter Notebooks (the notebooks, themselves are available through GitHub) that use the spaCy Python library to break down and analyze the transcriptions using Natural Language Processing techniques. There are two visualizations: the first charts word frequency for each dataset, and the second charts word frequency for the speeches in the Susan B. Anthony papers (see below).
Learn More, Read the Complete Post
Filed under: Data Files, Journal Articles, Libraries, News
About Gary Price
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area. He earned his MLIS degree from Wayne State University in Detroit. Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.
ADVERTISEMENT
Archives

ADVERTISEMENT