Special Collections: “Historical Costume Descriptors Bridge Gap Between Past and Present”
From Virginia Tech:
Virginia Tech fashion experts and computer scientists have teamed up to create a common language to describe clothing items in the university’s Oris Glisson Historic Costume and Textile Collection that range from centuries old to present day thanks to the University Libraries Collaborative Research Grant for Humanities and Social Sciences. Two Virginia Tech student positions were funded through this grant, allowing them to redescribe the garments, identify new terms, and perform quality control of the descriptions.
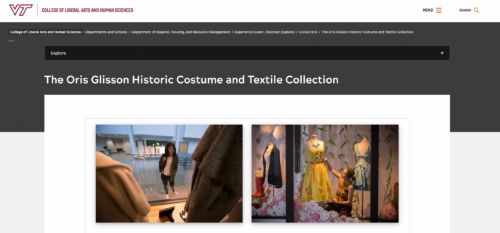
The objective is to compare language from the past with new language that we use today to describe costume artifacts across different time periods. The Oris Glisson Historic Costume and Textile Collection will be digitized and made available to the public, increasing accessibility and access. There are over 5,000 artifacts in the collection, making this a long-term project. The team has described and digitized approximately 200 items so far.
The collection consists of men’s, women’s, and children’s garments of all types, including evening wear, nightgowns, undergarments, and a rare 1840s wedding dress. There are accessories such as jewelry, glasses, scarves, and unique hats. Additionally, the team has created a “world closet” that contains items such as kimonos, Chinese skirts, and Korean handbags. The collection’s oldest artifact is a Peruvian burial garment fragment from 1180, although most of the garments date between 1840 and 2010.
[Clip]
Dina Smith-Glaviana, director of the Oris Glisson Historic Costume and Textile Collection, oversees the artifacts and the students who redescribes them. They examine them, identify other terms that might be more general, and pull language from the International Council of Museums terminology for costumes. Next, they create the new descriptions to put into their new metadata schema, Costume Core, which means building on existing standards to create a consistent way to catalog and code historic clothing.
[Clip]
The next step is to send the detailed descriptions on notecards to Chreston Miller, data and informatics consultant at University Libraries, where he and his student team oversee the natural language processing, also known as machine learning. There, they compare the cards and predict what Costume Core terms should be used to describe the item.
“This project is pretty interesting,” said Miller. “I’m a computer scientist, so when I tell people I am working with fashion, they are like, what connection is that? The people in Fashion Merchandising and Design have data they want to work with.”
Given the challenges of describing artifacts, especially ones of historic nature, Miller said one reason to have a controlled vocabulary is the descriptions that come with an artifact were written in a certain time period, so they have certain phrases for different aspects of the artifacts. “We read it today and we say, ‘What does this mean?’” said Miller.
Graduate student and University Libraries student employee, Madhuvanti Muralikrishnan ’23, is assisting Miller on the project while working on her master’s degree in computer science and applications. Her role is implementing the algorithms that map a given description to the Costume Core vocabulary.
Learn More, Read the Complete Post (about 1440 words) & View Video
See Also: The Oris Glisson Historic Costume and Textile Collection Website
Filed under: Archives and Special Collections, Data Files, Funding, Libraries, News
About Gary Price
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area. He earned his MLIS degree from Wayne State University in Detroit. Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.
ADVERTISEMENT
Archives

ADVERTISEMENT