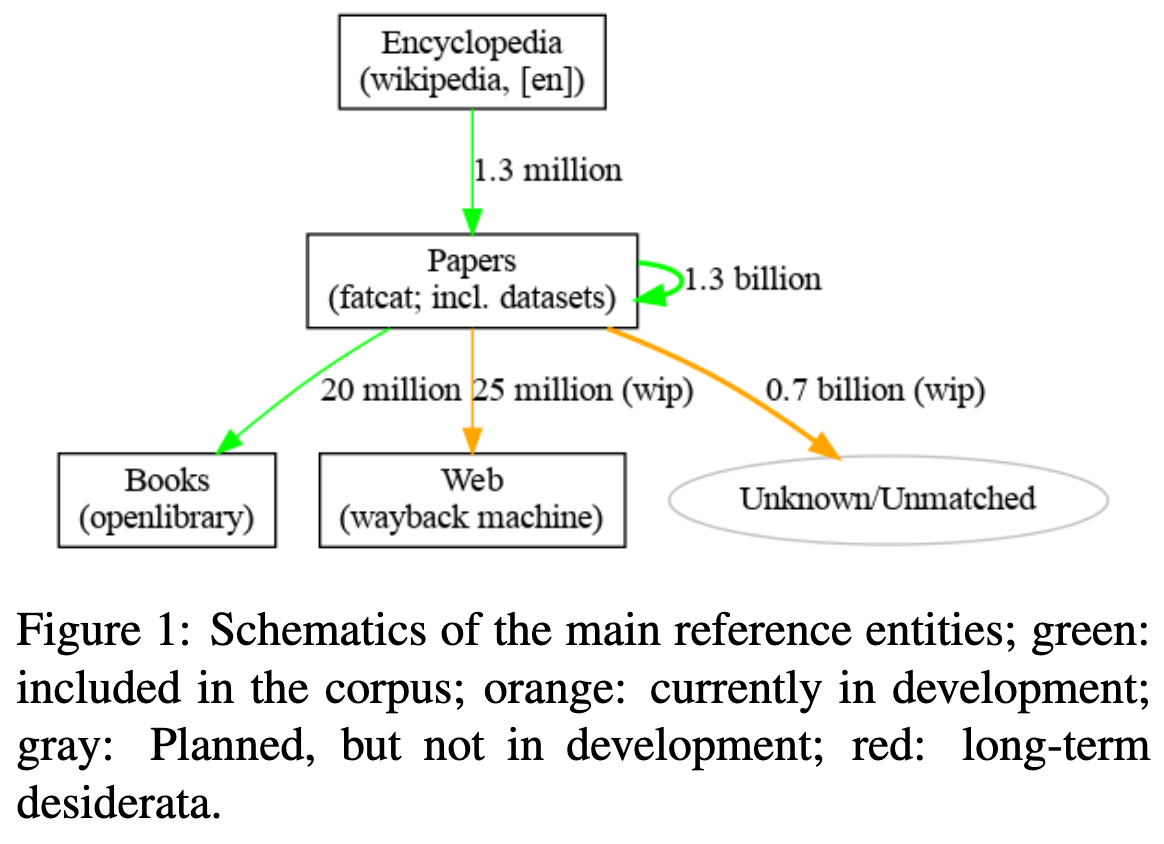
As part of its scholarly data efforts, the Internet Archive (IA) releases a first version of a citation graph dataset, named refcat, derived from scholarly publications and additional data sources. It is composed of data gathered by the fatcat cataloging project (the catalog that underpins IA Scholar), related web-scale crawls targeting primary and secondary scholarly outputs, as well as metadata from the Open Library project and Wikipedia. This first version of the graph consists of over 1.3B citations.
Source: arxiv.org/abs/2110.06595
We release this dataset under a CC0 Public Domain Dedication, accessible through Internet Archive. The source code used for the derivation process, including exact and fuzzy citation matching, is released under an MIT license. The goal of this report is to describe briefly the current contents and the derivation of the dataset.
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area.
He earned his MLIS degree from Wayne State University in Detroit.
Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.