Report: Releasing 1.8 Million Open Access Publications From Publisher Systems For Text and Data Mining
From the LSE Impact of Social Sciences Blog:
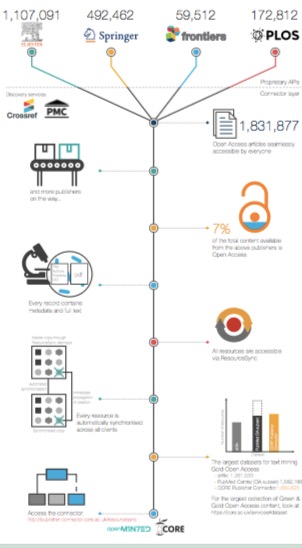
Open access and text mining of research papers have one thing in common: both aim to improve access to scientific knowledge for people. As a result, text mining is performed in large corpuses of text. In fact, many of the text mining tasks, such as semantic search, recommender systems, question answering, or content summarisation, are only able to realise their full potential when run on an as large a corpus of publications as possible. This means that text miners must typically invest considerable time, effort, and resources in collecting their corpus of interest. Sometimes, this task may prove impossible due to the technical restrictions and limitations of publisher platforms. According to a 2014 Jisc report, text miners can spend up to 90% of their total investigation time on the data collection.
To eliminate these extra steps and save time and money for text miners we have developed the CORE Publisher Connector, a toolkit service designed to assist text miners on accessing content though a single machine interface.
Development of the Publisher Connector was not easy.
Learn More, Read the Complete Post
Filed under: Data Files, Journal Articles, News, Open Access, Publishing
About Gary Price
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area. He earned his MLIS degree from Wayne State University in Detroit. Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.
ADVERTISEMENT
Archives

ADVERTISEMENT