I’m pleased to announce that as of today [April 20, 2017], the Wolfram Data Repository is officially launched! It’s been a long road. I actually initiated the project a decade ago—but it’s only now, with all sorts of innovations in the Wolfram Language and its symbolic ways of representing data, as well as with the arrival of the Wolfram Cloud, that all the pieces are finally in place to make a true computable data repository that works the way I think it should.
[Clip]
Of course, it’s taken many years and lots of work to make everything this smooth, and to get to the point where all those thousands of different kinds of data are fully integrated into the Wolfram Language—and Wolfram|Alpha.
[Emphasis Ours] But what about other data—say data from some new study or experiment? It’s easy to upload it someplace in some raw form. But the challenge is to make the data actually useful. And that’s where the new Wolfram Data Repository comes in. Its idea is to leverage everything we’ve done with the Wolfram Language—and Wolfram|Alpha, and the Wolfram Cloud—to make it as easy as possible to make data as broadly usable and computable as possible.
Its idea is to leverage everything we’ve done with the Wolfram Language—and Wolfram|Alpha, and the Wolfram Cloud—to make it as easy as possible to make data as broadly usable and computable as possible.
There are many parts to this. But let me state our basic goal. I want it to be the case that if someone is dealing with data they understand well, then they should be able to prepare that data for the Wolfram Data Repository in as little as 30 minutes—and then have that data be something that other people can readily use and compute with.
[Clip]
[Emphasis Ours] The Wolfram Data Repository that we’re launching today is a public resource, that lives in the public Wolfram Cloud. But we’re also going to be rolling out private Wolfram Data Repositories, that can be run in Enterprise Private Clouds—and indeed inside our own company we’ve already set up several private data repositories, that contain internal data for our company.
[Clip]
The Wolfram Data Repository is primarily intended for the case of definitive data that’s not continually changing. For data that’s constantly flowing in—say from IoT devices—we released last year the Wolfram Data Drop. Both Data Repository and Data Drop are deeply integrated into the Wolfram Language, and through our resource system, there’ll be some variants and combinations coming in the future.
[Clip]
The Wolfram Data Repository—and private versions of it—is basically a powerful, enabling technology for making data available in computable form. And sometimes all one wants to do is to make the data available.
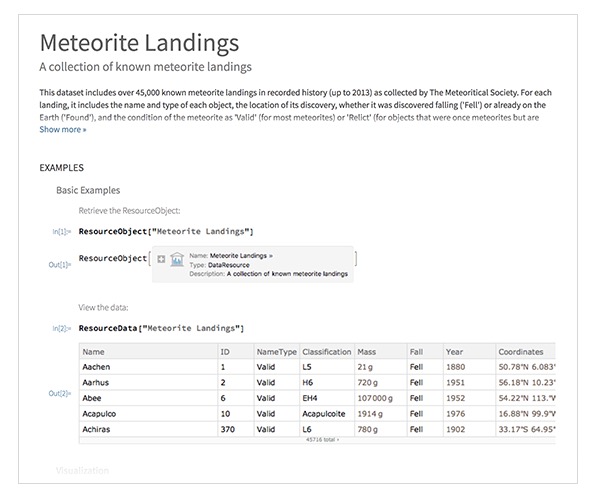
But at least in academic publishing, the main point usually isn’t the data. There’s usually a “story to be told”—and the data is just backup for that story. Of course, having that data backing is really important—and potentially quite transformative. Because when one has the data, in computable form, it’s realistic for people to work with it themselves, reproducing or checking the research, and directly building on it themselves. An Item From the Wolfram|Alpha Data Repository (Source: Wolfram|Alpha Blog; April 20, 2017) Academic Publishers
But, OK, how does the Wolfram Data Repository relate to traditional academic publishing? For our official Wolfram Data Repository we’re going to have definite standards for what we accept—and we’re going to concentrate on data that we think is of general interest or use. We have a whole process for checking the structure of data, and applying software quality assurance methods, as well as expert review, to it.
And, yes, each entry in the Wolfram Data Repository gets a DOI, just like a journal article. But for our official Wolfram Data Repository we’re focused on data—and not the story around it. We don’t see it as our role to check the methods by which the data was obtained, or to decide whether conclusions drawn from it are valid or not.
But given the Wolfram Data Repository, there are lots of new opportunities for data-backed academic journals that do in effect “tell stories”, but now have the infrastructure to back them up with data that can readily be used.
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area.
He earned his MLIS degree from Wayne State University in Detroit.
Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.