Research Tools: Find Linked Datasets Using the Recently Released LODAtlas
From a Post on the AIMS (Agricultural Information Management Standards) Blog:
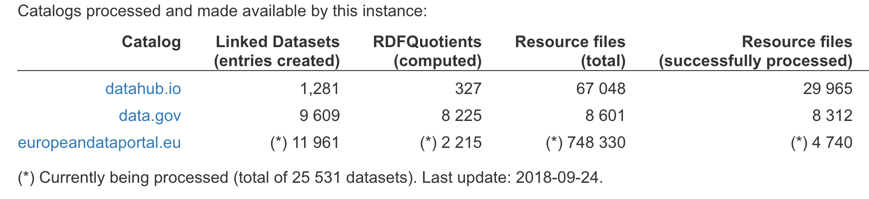
In October 2018, the 1.0 version of LODAtlas was released as an open source project under GNU General Public License v3.0. The LODAtlas’ source code is hosted on GitLab. LODAtlas was developed by project-team ILDA at Inria, CNRS and Université Paris-Sud; with contributions from project-team CEDAR (RDFQuotients).
[Clip]
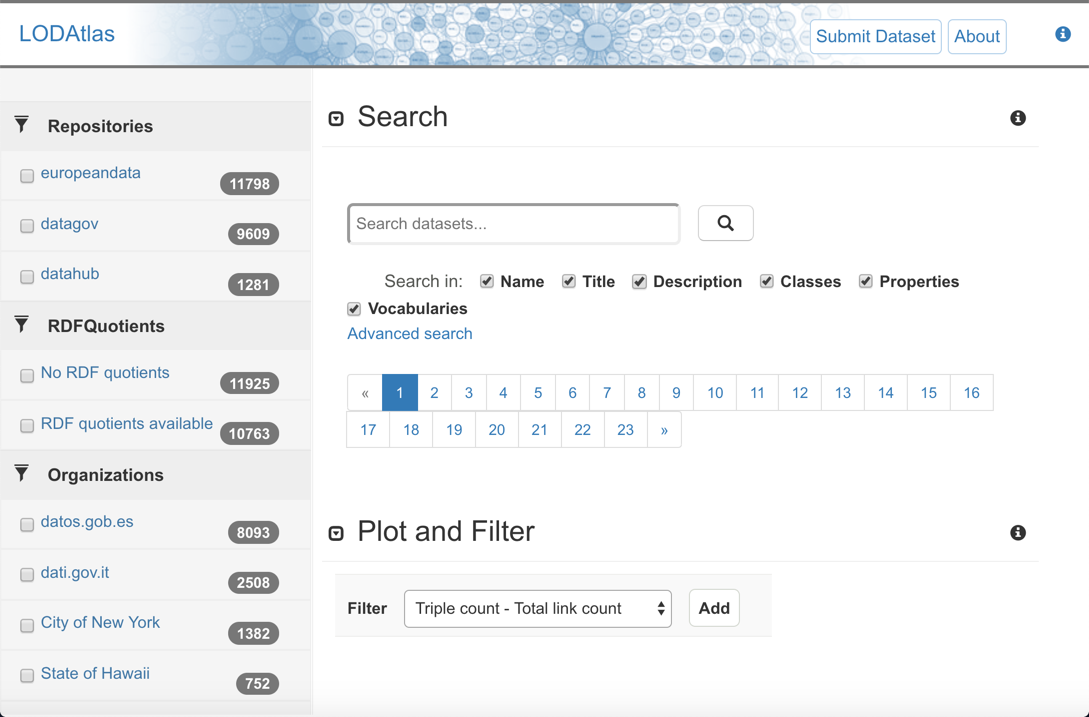
LODAtlas is a Web tool that helps users find linked datasets of interest through faceted browsing + keyword & URI search on the datasets’ metadata and their schema-level content.
The LODAtlas tool provides a set of interactive visualization widgets that help compare datasets along different criteria:
- number of triples,
- last update,
- interlinking with other datasets in the Linked Open Data (LOD) cloud, etc..
Users can also get an idea of the contents of a given dataset thanks to a visual summary of the statements it contains.
[Clip]
LODAtlas REST API provides programmatic access to most of the data that can be visualized.
Learn More, Read the Complete Blog Post
See Also: Conference Paper: Browsing Linked Data Catalogs with LODAtlas
Presented at the ISWC 2018 – 17th International Semantic Web Conference, Oct 2018, Monterey, United States
The Web of Data is growing fast, as exemplified by the evolution of the Linked Open Data (LOD) cloud over the last ten years. One of the consequences of this growth is that it is becoming increasingly difficult for application developers and end-users to find the datasets that would be relevant to them. Semantic Web search engines, open data catalogs , datasets and frameworks such as LODStats and LOD Laundromat, are all useful but only give partial, even if complementary, views on what datasets are available on the Web. We introduce LODAtlas, a portal that enables users to find datasets of interest. Users can make different types of queries about both the datasets’ metadata and contents, aggregated from multiple sources. They can then quickly evaluate the matching datasets’ relevance, thanks to LODAtlas’ summary visualizations of their general metadata, connections and contents.
Direct to Full Text Paper (via Conference Website)
17 pages; PDF.
Note: A paywalled version of the paper is available via Lecture Notes in Computer Science book series (LNCS, volume 11137) from Springer.
Filed under: Data Files, Journal Articles, Management and Leadership, News, Patrons and Users
About Gary Price
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area. He earned his MLIS degree from Wayne State University in Detroit. Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.
ADVERTISEMENT
Archives

ADVERTISEMENT