SherlockNet: British Library Flickr Commons Image Dataset UPDATED With More Tags and Thousands of Captions
From a British Library “Digital Scholarship” Blog Post:
We have some exciting updates regarding SherlockNet, our ongoing efforts to using machine learning techniques to radically improve the discoverability of the British Library Flickr Commons image dataset.
Over the past 2 months we’ve been working on expanding and refining the set of tags assigned to each image. Initially, we set out simply to assign the images to one of 11 categories, which worked surprisingly well with less than a 20% error rate. But we realized that people usually search from a much larger set of words, and we spent a lot of time thinking about how we would assign more descriptive tags to each image.
[Clip]
For the past few weeks we’ve been working on the incorporation of ~20 million tags and related images and uploading them onto our website. Luckily Amazon Web Services provides comprehensive computing resources to take care of storing and transferring our data into databases to be queried by the front-end.
In order to make searching easier we’ve also added functionality to automatically include synonyms in your search. For example, you can type in “lady”, click on Synonym Search, and it adds “gentlewoman”, “ma’am”, “madam”, “noblewoman”, and “peeress” to your search as well. This is particularly useful in a tag-based indexing approach as we are using.
As our data gets uploaded over the next days, you should begin to see our generated tags and related images show up on the website. You can click on each image to view it in more detail, or on each tag to re-query the website for that particular tag. This way users can easily browse relevant images or tags to find what they are interested in.
[Clip]
We will also be working on adding more advanced search capabilities via wrapper calls to the Flickr API. Proposed functionality will include logical AND and NOT operators, as well as better filtering by machine tags.
As mentioned in our previous post, we have been experimenting with techniques to automatically caption images with relevant natural language captions. Since an Artificial Intelligence (AI) is responsible for recognising, understanding, and learning proper language models for captions, we expected the task to be far harder than that of tagging, and although the final results we obtained may not be ready for a production-level archival purposes, we hope our work can help spark further research in this field.
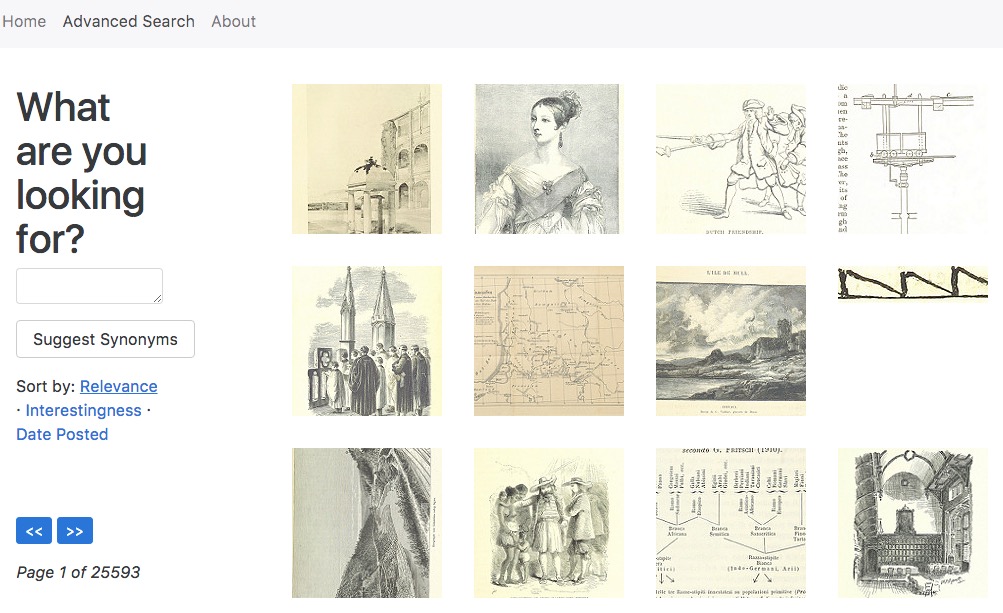
Learn MUCH More About the Update to SherlockNet
Direct to SherlockNet Public Search Interface
See Also: SherlockNet: tagging and captioning the British Library’s Flickr images (August 22, 2016)
See Also: Research Paper: “SherlockNet: Exploring 400 Years of Western Book Illustrations With Convolutional Neural Networks”
Filed under: Data Files, Journal Articles, Libraries, News, Patrons and Users
About Gary Price
Gary Price (gprice@gmail.com) is a librarian, writer, consultant, and frequent conference speaker based in the Washington D.C. metro area. He earned his MLIS degree from Wayne State University in Detroit. Price has won several awards including the SLA Innovations in Technology Award and Alumnus of the Year from the Wayne St. University Library and Information Science Program. From 2006-2009 he was Director of Online Information Services at Ask.com.
ADVERTISEMENT
Archives

ADVERTISEMENT